More Oxide at Home: My Pi is a Wireless Crucible
Welcome back to me making bad decisions with Oxide software. Today we’ll have a look at Crucible, a networked storage service. Now, “network storage” can mean a lot of things, from low level block devices to high level bucket stores. Crucible sits at the low level end of the spectrum, and is intended for stuff like block devices for virtual machine. I’m going to tell you what I’ve learned from digging through the crucible git repository and talking to Josh Clulow (seriously, thanks for answering all my 2AM questions). Then for dessert I’m going to turn a Raspberry Pi into a WiFi USB drive backed by a Crucible datastore on my OpenIndiana box, complete with block-level encryption and data replication.
How Does Crucible
Before we start using Crucible, I’ll give you a high level overview of the project as I understand it. I’ll take a look at the on-disk data format, and I’ll explain a bit about replication so you know the overhead we’re working with. Now, I didn’t write Crucible, nor have I read every line of code, so please mind the knowledge gap as you tread through this section. I’ll keep this post updated if I get word that something isn’t quite right.
Layer Cake
From a high level you’ve got four layers to think about.
At the very bottom is the real physical backing storage. These are real bytes, used by real people, and they exist in a place (or multiple places), and they actually store data. Whether that backing storage is a disk, a slab of ram, an S3 bucket, or an array of redstone torches in minecraft, it doesn’t particularly matter as long as the next layer up knows how to use it. For the purposes of crucible, it’s just a folder on a machine.
The next layer is Downstairs. Downstairs runs on whatever machine has the real data. It stores it in a format called the Crucible Region format (TM) (tm), and spends its time waiting around listening for requests from Upstairs. Crucible is designed with replication in mind, so you can have multiple Downstairs instances all providing access to the same logical data replicated across multiple physical nodes.
Let’s climb our way up to Upstairs, the third layer. Upstairs is a runtime that applications can use to communicate with Downstairs. It implements the network protocol as well as higher level features like encryption, data verification, replication to multiple Downstairs regions. Apps that want to use Crucible (called Guests) import Upstairs, launch it in a tokio runtime, and then communicate with that task with the API. There’s no Upstairs daemon or anything like that, it all stays in-process.
And finally at the top is the “guest” application. This is the code that wants to store some data. For example, it could be a virtual disk driver for a virtual machine, something Propolis has already implemented. You could also use it to implement a Network Block Device server, which again has already been done. Basically, any program that wants to store some blocks of data, that’s the guest application. It imports Upstairs, which talks to Downstairs, which talks to the raw storage. Now we’ve got bytes flowing around and they’re doing something meaningful.
Crucible Regions
What’s in a Region? Let’s create one and find out!
$ mkdir var
$ cargo run -p crucible-downstairs -- create -u $(uuidgen) -d var/region1
Created new region file "var/region1/region.json"
UUID: 0ea9975b-43dc-e237-d2d3-e693c0b65959
Blocks per extent:100 Total Extents: 1
Ah json, we meet again.
$ cat var/region1/region.json
{
"block_size": 512,
"extent_size": {
"value": 100,
"shift": 9
},
"extent_count": 15,
"uuid": "0ea9975b-43dc-e237-d2d3-e693c0b65959",
"encrypted": false
}
$ tree var/region1/
var/region1/
├── 00
│ └── 000
│ ├── 000
│ ├── 000.db
│ ├── 001
│ ├── 001.db
│ ├── 002
│ ├── 002.db
│ ├── 003
│ ├── 003.db
│ ├── 004
│ ├── 004.db
│ ├── 005
│ ├── 005.db
│ ├── 006
│ ├── 006.db
│ ├── 007
│ ├── 007.db
│ ├── 008
│ ├── 008.db
│ ├── 009
│ ├── 009.db
│ ├── 00A
│ ├── 00A.db
│ ├── 00B
│ ├── 00B.db
│ ├── 00C
│ ├── 00C.db
│ ├── 00D
│ ├── 00D.db
│ ├── 00E
│ └── 00E.db
├── region.json
└── seed.db
So what can we deduce from this?
First off, we’ve an extent_count of 15, and we’ve got 15 pairs of files 00/000/. Those are probably the extents themselves. Next, the extent_size is 100 shift 9. Let’s do some maths:
$ wc -c var/region1/00/000/000
51200 var/region1/00/000/00
$ python -c 'print(100 << 9)'
51200
So yeah those are our extents, they’ve all got a uniform size, and that size is calculated as value * 2^shift. Something else to note is 2^9 is 512, the same value as our block size. Downstairs told us each extent stores 100 blocks, and 100 * 512 = 51200, so the math checks out. Ok, so the files with no file extensions are the data, what about the db files? OpenIndiana’s file command can’t identity them, but the one on my Linux box can:
# file 000.db
000.db: SQLite 3.x database, last written using SQLite version 3038005
Haha just standard SQLite. That means we can look inside pretty easily.
$ sqlite3 region1/00/000/000.db
SQLite version 3.31.1 2020-01-27 19:55:54
Enter ".help" for usage hints.
sqlite> .output extent-db.txt
sqlite> .dump
sqlite> .exit
$ cat extent-db.txt
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE metadata (
name TEXT PRIMARY KEY,
value INTEGER NOT NULL
);
INSERT INTO metadata VALUES('ext_version',1);
INSERT INTO metadata VALUES('gen_number',0);
INSERT INTO metadata VALUES('flush_number',0);
INSERT INTO metadata VALUES('dirty',0);
CREATE TABLE encryption_context (
counter INTEGER,
block INTEGER,
nonce BLOB NOT NULL,
tag BLOB NOT NULL,
PRIMARY KEY (block, counter)
);
CREATE TABLE integrity_hashes (
counter INTEGER,
block INTEGER,
hash BLOB NOT NULL,
PRIMARY KEY (block, counter)
);
COMMIT;
I checked out seed.db and the dump of that is exactly the same. Maybe it’s there so they can cheaply copy that file in-place to initialize new extents? Literally yes. While I’m looking at the code, we can get some more information about the extent metadata from the comments, but I’ll let you read that yourself if you’re particularly interested.
So a crucible region is a bunch of extent files that store some data blocks. Each extent has a corresponding SQLite database to keep hold of some basic extent metadata and any integrity hashes. This encryption_context table suggests crucible can handle encrypting data, rather than relying on the underlying data store for that. Then there’s a basic JSON file that specifies the parameters of the region, and that’s about it! This encryption thing has me interested though- is encryption performed Downstairs or Upstairs?
Encryption
With a quick search for “encrypt”, I have my answer: Upstairs. Checking the encrypt_in_place() function, we see that Upstairs encrypts the data before it sends it off to Crucible. But! It also sends the hash of the data AFTER encryption, so that Crucible can do integrity checks without the decryption key. Interesting.
So remember, Upstairs runs with your application, not your datastore. Since Upstairs handles encryption, this means that in one fell swoop you get both encryption at rest as well as some encryption in transit. If an attacker compromises your Downstairs, or intercepts your transmissions, they don’t immediately get access to your data. They’ve got to get ahold of the encryption keys first. I’ve been told that transport-layer encryption and authentication mechanisms for the protocol are also on the roadmap, but I don’t know how much of that is done.
But, there are some attacks that are currently possible. The code itself points out two possibilities:
// XXX because we don't have block generation numbers, an attacker
// downstairs could:
//
// 1) remove encryption context and cause a denial of service, or
// 2) roll back a block by writing an old data and encryption context
So an attacker that compromises Downstairs could hold on to some valid data and its associated encryption context, and then present that later to Upstairs to show it an older data state. That’s a bit abstract- how could someone actually exploit this?
Well, indulge me as I let my infosec side through a bit. Let’s say our hypothetical attacker Alice has the following access:
- Control of Downstairs
- Some unprivileged shell on Upstairs
Upstairs in this scenario is running Debian or Ubuntu, with the rootfs backed by Crucible. Whenever someone installs a package with apt-get, an entry is logged in /var/log/apt/history.log, which is by default world-readable. With this access, Alice can watch as packages are installed and correlate package installations with data writes.
A few months later, someone discovers a serious security flaw in something installed on the system. The system administrators are on their game and rapidly deploy a patch to it, but even if they hadn’t, automatic upgrades would have kicked in soon enough. By the time a working proof of concept is published openly to the world, the system is already immune.
But Alice, now she has a trick up her sleeve. Once she has a working exploit, she can roll back the system’s version of that package and take advantage of it. As long as she has access to Downstairs, she’s also free to sit on that exploit and wait for the perfect time to strike. When an attacker is under pressure, they make mistakes; here that pressure is removed.
So there’s a fun story to get you thinking about how these attacks can play out. But it’s here that I want to remind you that this is an attack they’re already thinking about. They could make changes to crucible to defend against this sort of thing, or they could decide to implement that defense in another layer of the software stack. Something more interesting is to imagine attacks they haven’t thought of, but I’ll leave that as an exercise for the reader. ;)
Data Integrity and Replication
Crucible’s design is incredibly straightforward and integrity and replication are no exceptions. An Upstairs application can replicate data out to multiple Downstairs nodes, typically at least three. Downstairs instances don’t talk to each other, so Upstairs just writes the same data out to each node. This does linearly increase your network traffic from Upstairs with your number of nodes, but it also means there’s no complicated consensus protocol between Downstairs nodes. A fair trade, when you’ve got cutting edge network equipment.
When reading data, Upstairs sends read requests out to all the Downstairs nodes at once. It’ll give the guest application the data from the first Downstairs node that returns something valid, but it’ll also collect the responses from the remaining nodes to make sure they’re returning what they’re supposed to. Data is only valid if its hash is valid, and if it decrypted properly.
There’s also some extra checks when a Downstairs node connects to make sure all the nodes are in a consistent state. If you’re curious give this comment a read for the details.
Let’s Crucible!
Downstairs
That’s enough theory for one day, now let’s do something with it! First we need to create some regions. I’m feeling like I want a 128GiB data store, and I’ll be using 128MiB extents so there’s not so many files to deal with. That means we’ll need 1024 extents, each containing 262144 blocks. Also, I learned you need to tell it in advance when a region will be encrypted. So, here’s three regions.
vi@illumos$ cargo run -q -p crucible-downstairs -- create -d var/region1 -u $(uuidgen) --extent-size 262144 --extent-count 1024 --block-size 512 --encrypted true
Created new region file "var/region1/region.json"
UUID: 8c459730-4000-6772-9368-a3c0083f6e8c
Blocks per extent:262144 Total Extents: 1024
vi@illumos$ cargo run -q -p crucible-downstairs -- create -d var/region2 -u $(uuidgen) --extent-size 262144 --extent-count 1024 --block-size 512 --encrypted true
Created new region file "var/region2/region.json"
UUID: 8600e7f9-f6c0-c7b2-f4d5-c8f4466d829a
Blocks per extent:262144 Total Extents: 1024
vi@illumos$ cargo run -q -p crucible-downstairs -- create -d var/region3 -u $(uuidgen) --extent-size 262144 --extent-count 1024 --block-size 512 --encrypted true
Created new region file "var/region3/region.json"
UUID: fffd19ea-84d2-c765-fc8d-fe815b7f1b62
Blocks per extent:262144 Total Extents: 1024
Let’s check on that data.
vi@illumos$ du -h var/
29.3M var/region1/00/000
29.3M var/region1/00
29.3M var/region1
29.3M var/region2/00/000
29.3M var/region2/00
29.3M var/region2
29.3M var/region3/00/000
29.3M var/region3/00
29.3M var/region3
88.0M var
vi@illumos$ wc -c < var/region1/00/000/000
134217728
Hah, nice. So the files are allocated, but since they’re all full of zeroes, we’re not actually paying for that storage space yet. This is just my file system at work. Since everything in ZFS is copy-on-write, ZFS doesn’t have a reason to pre-allocate the data.
Now we can spin up some Downstairs nodes, each on their own port, and each backed by a different region. I’ve listed three commands here, but I ran them each from their own terminal.
vi@illumos$ cargo run --release -q -p crucible-downstairs -- run -p 3810 -d var/region1/
Opened existing region file "var/region1/region.json"
UUID: 8c459730-4000-6772-9368-a3c0083f6e8c
Blocks per extent:262144 Total Extents: 1024
Using address: 0.0.0.0:3810
No SSL acceptor configured
listening on 0.0.0.0:3810
Repair listens on 0.0.0.0:7810
vi@illumos$ cargo run --release -q -p crucible-downstairs -- run -p 3820 -d var/region2/
Opened existing region file "var/region2/region.json"
UUID: 8600e7f9-f6c0-c7b2-f4d5-c8f4466d829a
Blocks per extent:262144 Total Extents: 1024
Using address: 0.0.0.0:3820
No SSL acceptor configured
listening on 0.0.0.0:3820
Repair listens on 0.0.0.0:7820
vi@illumos$ cargo run --release -q -p crucible-downstairs -- run -p 3830 -d var/region3/
Opened existing region file "var/region3/region.json"
UUID: fffd19ea-84d2-c765-fc8d-fe815b7f1b62
Blocks per extent:262144 Total Extents: 1024
Using address: 0.0.0.0:3830
No SSL acceptor configured
listening on 0.0.0.0:3830
Repair listens on 0.0.0.0:7830
Once again I am pleased with how easy this is to do. Now let’s get weird with it.
No Big Deal
I don’t really feel like writing my own code to use Crucible, but luckily I don’t have to. As I mentioned earlier, there’s a reference implementation of the Network Block Device protocol that we can run to get a regular ol block device to use however we’d like. From now on we’ll be working from my Raspberry Pi 4, and the first thing we’ve got to do is build Crucible over there. Then we can run the NBD server!
vi@pi$ cargo build --release
vi@pi$ cd target/release
vi@pi$ ./crucible-nbd-server -k 'buttslol' -t 172.16.254.177:3810 -t 172.16.254.177:3820 -t 172.16.254.177:3830
Crucible runtime is spawned
The guest is requesting activation with gen:0
thread 'crucible-tokio' panicked at 'Key length must be 32 bytes!', upstairs/src/lib.rs:151:17
Ok it looks like we’re giving this thing a raw 256-bit AES key. Let’s try with a 32-byte long string?
vi@pi$ ./crucible-nbd-server -k 'Key length must be 32 bytes! lol' -t 172.16.254.177:3810 -t 172.16.254.177:3820 -t 172.16.254.177:3830
Crucible runtime is spawned
The guest is requesting activation with gen:0
thread 'crucible-tokio' panicked at 'could not base64 decode key!: InvalidByte(3, 32)', upstairs/src/lib.rs:148:37
Nope, it actually wants 32 bytes that have been base64 encoded. Works for me!
vi@pi$ echo -n 'Key length must be 32 bytes! lol' | base64
S2V5IGxlbmd0aCBtdXN0IGJlIDMyIGJ5dGVzISBsb2w=
vi@pi$ ./crucible-nbd-server -k 'S2V5IGxlbmd0aCBtdXN0IGJlIDMyIGJ5dGVzISBsb2w=' -t 172.16.254.177:3810 -t 172.16.254.177:3820 -t 172.16.254.177:3830
172.16.254.177:3810[0] looper connecting to 172.16.254.177:3810
172.16.254.177:3820[1] looper connecting to 172.16.254.177:3820
Wait for all three downstairs to come online
[...]
There we go! But we don’t have a block device yet. For that we’ll use nbd-client.
vi@pi$ sudo apt install nbd-client
vi@pi$ sudo modprobe nbd
vi@pi$ sudo nbd-client -C 1 -b 512 -p localhost /dev/nbd0
vi@pi$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nbd0 43:0 0 128G 0 disk
mmcblk0 179:0 0 59.5G 0 disk
├─mmcblk0p1 179:1 0 256M 0 part /boot
└─mmcblk0p2 179:2 0 59.2G 0 part /
Now we can do some tests to see what kind of bandwidth we get. Let’s try 16MiB of data.
# write test
vi@pi$ sudo dd if=/dev/zero of=/dev/nbd0 oflag=direct conv=fsync bs=4M count=4
4+0 records in
4+0 records out
16777216 bytes (17 MB, 16 MiB) copied, 31.2571 s, 537 kB/s
# read test
vi@pi$ sudo dd if=/dev/nbd0 of=/dev/null iflag=direct bs=4M count=4
4+0 records in
4+0 records out
16777216 bytes (17 MB, 16 MiB) copied, 9.73241 s, 1.7 MB/s
Wow. That write speed is terrible. Like, 40 times slower than my slowest SD card writer. The read is a bit better but still not great. This is for the most part not crucible’s fault; no, this is just the harsh realities of the Pi 4 WiFi. Even with 802.11ac, I only get about 10MiB/s up and 6-8MiB/s down over the wifi. That’s worse than 100mbit ethernet.
Remembering that each read gets replicated three times, we’re actually pulling down 5.1MiB/s of block data from Downstairs, so we’re getting good use out of our download bandwidth. Writes are a bit rougher, because we have to wait for all three writes to finish before it’s considered done. Granted, we have a much higher round-trip latency on WiFi than we’d get on a wire, and Crucible isn’t designed for this. Still, this could probably be making better use of the bandwidth available.
Regardless, this is still enough to do something, so let’s introduce the last piece of the puzzle.
Go Go Gadget: Mass Storage Device
Linux has this thing called USB Gadget Mode, where it can act like a USB Peripheral on a USB On-The-Go (OTG) port. The Raspberry Pi 4’s USB-C port is actually an OTG port, so the Pi 4 can do this. With the Mass Storage Gadget, Linux can present a USB Mass Storage Device backed by any block device or raw data file on the system. More plainly, we can turn our Pi into a USB Hard Drive. This is extremely well-trodden ground, so I’ve been following thagrol’s USB Mass Storage Gadget guide.
So let’s turn Crucible into a bootable USB Drive shall we? Coming in at only 21MB, TinyCoreLinux is an excellent candidate for this.
vi@pi$ sudo dd if=TinyCore-current.iso of=/dev/nbd0 bs=1M oflag=direct conv=fsync
22+0 records in
22+0 records out
23068672 bytes (23 MB, 22 MiB) copied, 51.6277 s, 447 kB/s
Now we need to make the Crucible NBD server and NBD client run at boot, and set up the USB gadget. I set up a couple runit services to handle this.
vi@pi$ cat /etc/sv/crucible/run
#!/bin/sh
exec /home/vi/crucible/target/release/crucible-nbd-server -k 'S2V5IGxlbmd0aCBtdXN0IGJlIDMyIGJ5dGVzISBsb2w=' -t 172.16.254.177:3810 -t 172.16.254.177:3820 -t 172.16.254.177:3830
vi@pi$ cat /etc/sv/nbd/run
#!/bin/bash
sv start crucible
modprobe nbd
while ! nbd-client -C 1 -b 512 -p localhost /dev/nbd0 &>/tmp/wtf.txt; do
sleep 1
done
sleep 1
modprobe g_mass_storage file=/dev/nbd0
permafrost
Last but not least, I added dtoverlay=dwc2,dr_mode=peripheral to my /boot/config.txt. Believe it or not, that’s everything. I plugged my Pi into my desktop, pressed the power button, and waited in anticipation. A few tens of seconds later, I had a desktop.
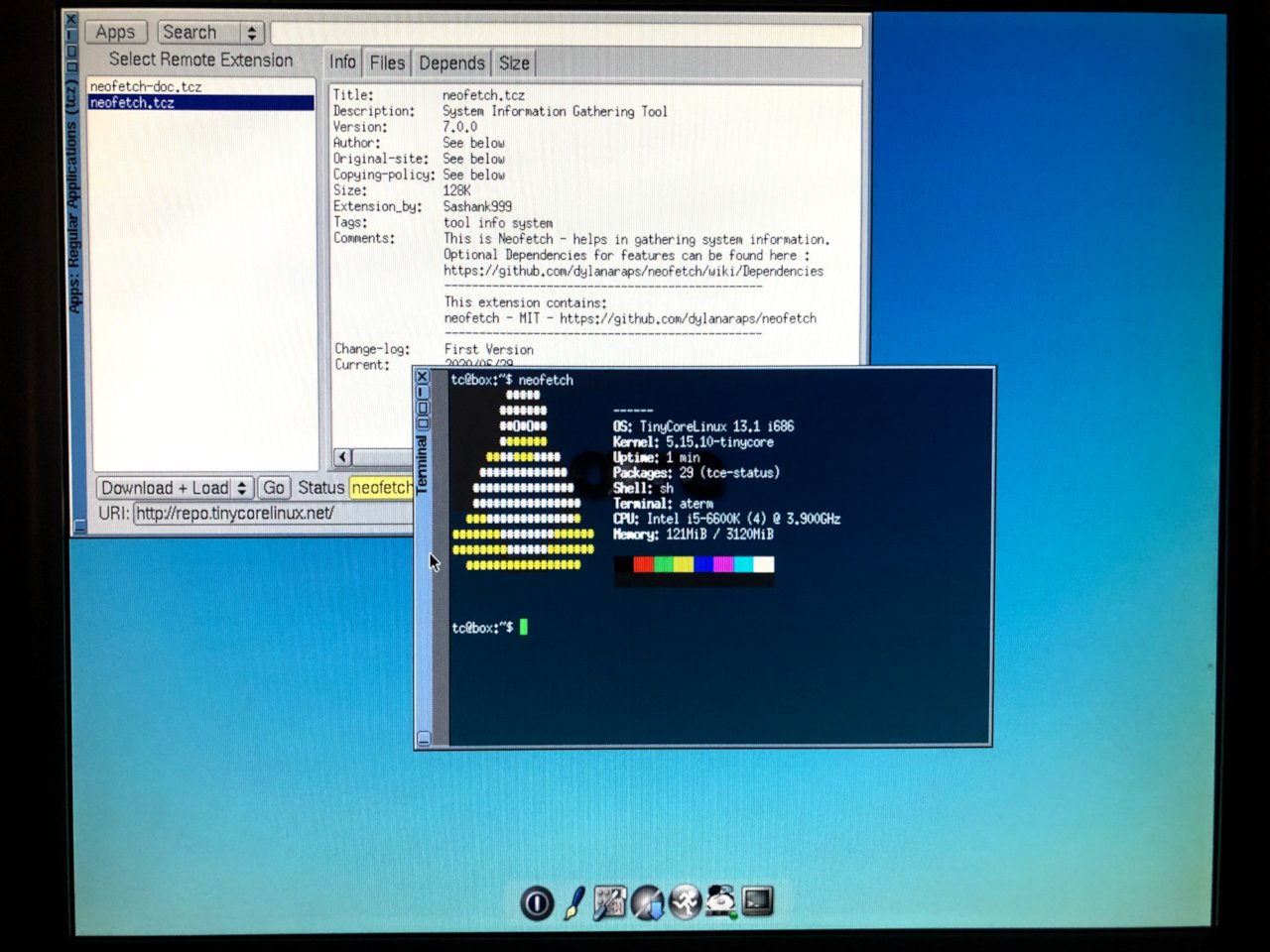
I’m not sure why I was surprised that this worked, but I was. I’m streaming data real time from an illumos server in the other room to my raspberry pi, which is presenting it as one of the slowest USB devices in the world, and somehow this all just works.
Faster.
Now that I’ve satisfied my dark desire to make a wireless USB drive, let’s add an ethernet cable and see what this stack can really do. I tested with a lot of extent and block sizes to find the fastest for this setup, and disabled encryption for good measure. After all that, here’s the best I got:
- 4096-byte block size
- 16384-block extent size
- 6.9 MiB/s read-speed
- 3.8 MiB/s write-speed
That’s much better than on WiFi, but it could be better still. At peak read we’re still only using about 170 megabits/s raw network bandwidth, less than 1/5 the bandwidth available. Crucible’s NBD server is intended for testing, not production, so I thought maybe it wasn’t making the best use of the Upstairs layer that it could. I was right.
Turns out the Crucible team hasn’t actually implemented the NBD protocol themselves. Instead, they used the nbd crate, which takes any struct with Read + Write + Seek implemented and turns it into an NBD server. This is really great for getting something working fast, but the problem is everything is synchronous. This model just doesn’t allow you to pipeline your IO operations. What are our other options?
I didn’t want to implement the NBD protocol myself, but luckily there’s a lot of nbd crates out there. nbd-async seemed promising at first, but while it does use async IO, it’s structured in such a way that it can only serve one NBD request at a time. I could have modified it to support parallel requests, but there’s a better option: nbdkit.
nbdkit is the go-to standard for writing nbd servers. It’s been around the block, and supports writing servers in a lot of languages, including rust. You provide a dynamic library in the plugin format it understands, and it handles the rest. I naiively assumed that using it with rust would be a frustrating endeavor full of unsafe code and C FFI, but that could not be further from the truth. All you have to do is implement their Server trait, and their plugin!() macro takes care of all the FFI glue to expose it as an nbdkit plugin.
I did have to rework the NBD server to be a dynamic library instead of an executable. That was interesting. There’s no main() function, and the load() function doesn’t have a direct way to give state to the rest of the server, so I hacked a couple of global mutexes in and called it a day. Also, the rust nbdkit library doesn’t build properly on aarch64 because they made some bad assumptions about C types (c_char isn’t u8 everywhere, sorry y’all), so I had to work around that. Anyways, after that rework I was rewarded with… well, some benefit, mostly in read speeds. With 512-byte blocks I got
- 7.9 MiB/s read-speed
- 5.1 MiB/s write-speed
And with 4096-byte blocks, I got
- 18.4 MiB/s read-speed
- 4.1 MiB/s write-speed
You can see my code on my github fork, complete with hardcoded downstairs IP-addresses, since I didn’t feel like dealing with nbdkit configuration. It’s a bit hacky but it did the trick.
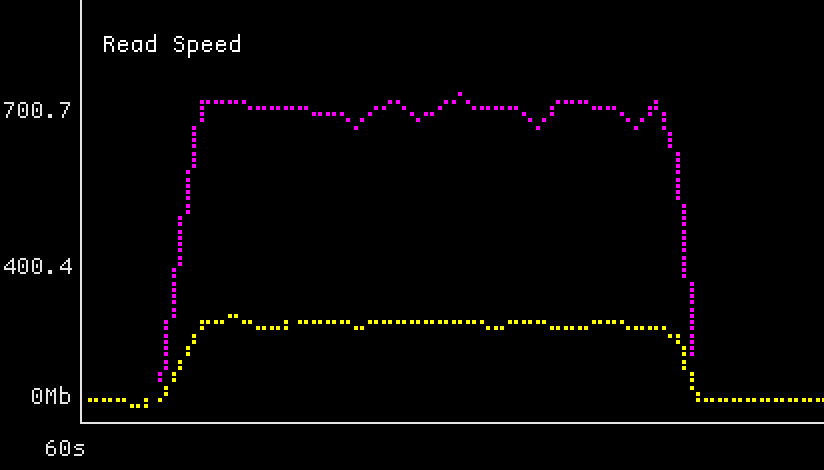
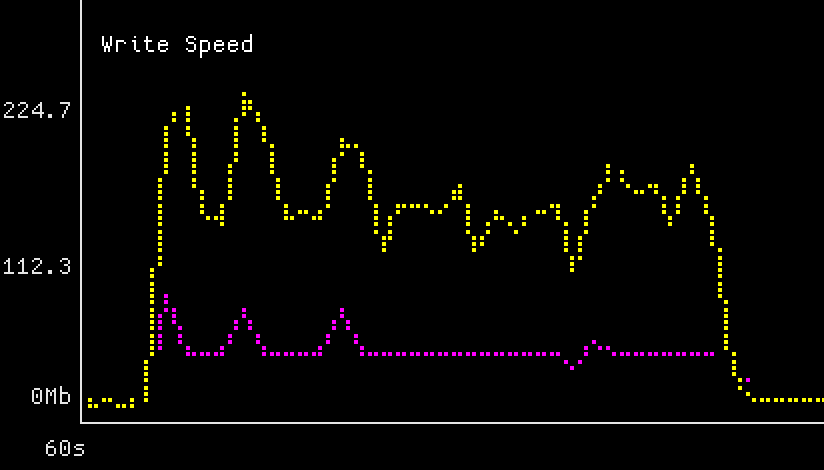
It’s interesting that the reads and writes are now scaling opposite of each other with block size. With 4096-byte blocks we got up to 500mbit/s raw read bandwidth, accounting for replication, so that’s pretty good! But I have to conclude I’m running into a bottleneck with either Upstairs or Downstairs, because there is definitely still bandwidth left in my gigabit networking that Crucible could be using. The writes in particular are very inconsistent, with the network graph bouncing up and down throughout the write. But hey, that’s what you get when you take something that tells you not to use it yet and use it anyway!
I’m tabling this project for now, but if I can squeeze a bit more out of it in the future I have some other silly ideas for Crucible that it was definitely not meant for. Thanks as always for stopping by!